
Мне нравится обсуждать с ChatGPT тренировки в зале, питание и их влияние на мою работоспособсность. Он помогает анализировать повторяющиеся паттерны и отслеживать изменения в поведении, которые я сам не замечаю. Но чтобы советы были более точные, ему нужен контекст. Что именно я делал, как реагировал организм, как менялось самочувствие и концентрация.
Для этого я создал закрытую группу в Telegram и начал там вести заметки. Например: «концентрация упала, сделал кофе» и через час: «эффекта ноль, всё ещё туплю».
Дальше я связал эту группу с ChatGPT. Теперь, когда спрашиваю совета, он уже знает контекст — и отвечает гораздо точнее.
Что получилось
Пишу заметки в приватную Telegram-группу. Бот ловит каждое сообщение и сохраняет его в файл diary.md на моём сервере. Ссылку на файл я добавил в раздел «Персонализация» в ChatGPT.
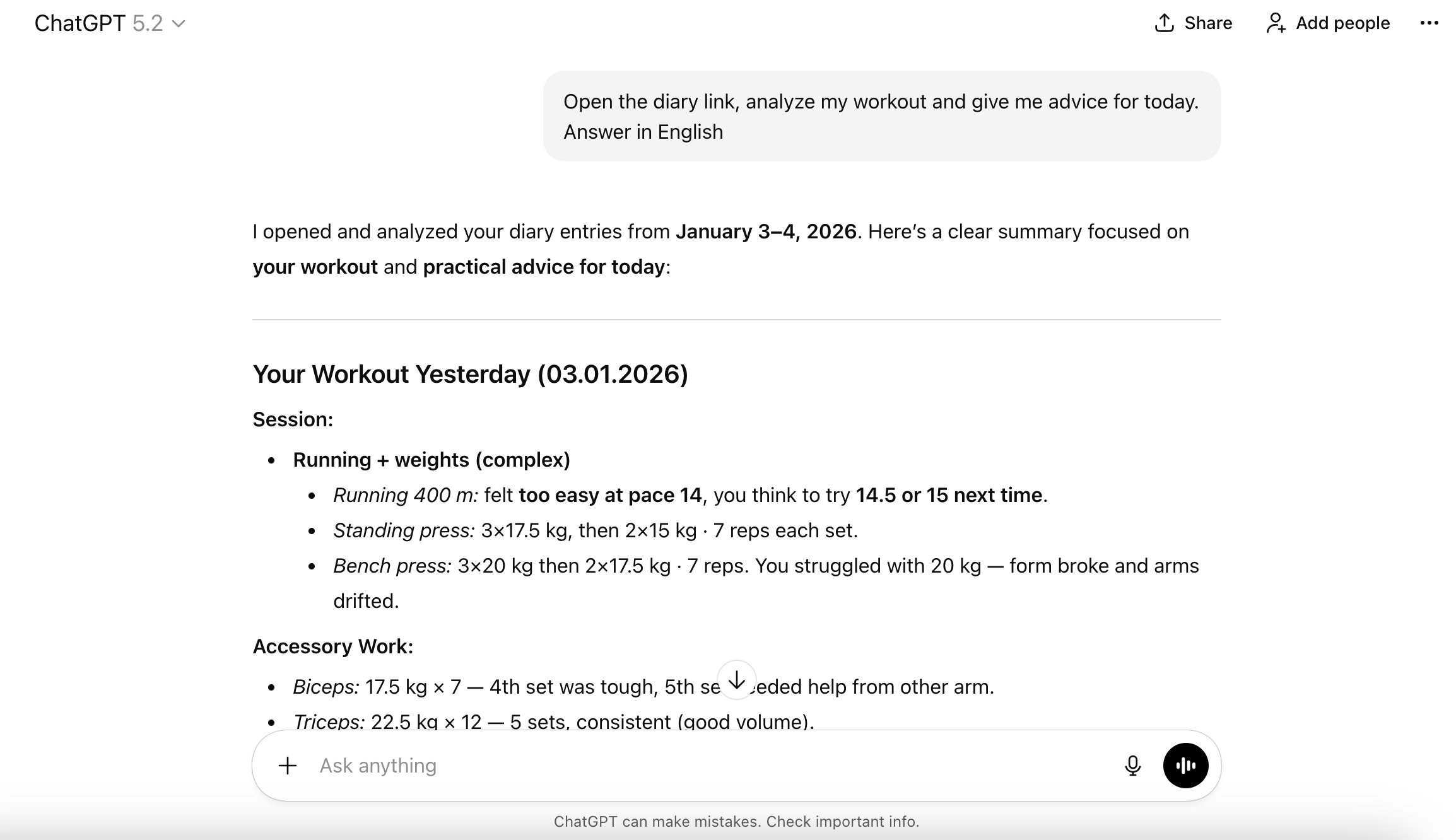
Настройки Telegram
Создал группу в Telegram. Создал бота через @BotFather. Зашёл в его профиль → Edit Bot → Bot Settings → Group Privacy → Turn off. По умолчанию боты не могут читать сообщения в группе, поэтому эту настройку нужно отключить.
Через профиль бота добавил его в свою группу. Бот не видит историю сообщений — только те, которые появились после его добавления. Это нужно учесть.
Через @BotFather скопировал API-ключ бота.
Long polling
На сервере крутится простой Node.js скрипт. Он использует long polling: делает запрос к Telegram API с параметром timeout=30. Telegram не отвечает сразу, а держит соединение открытым до 30 секунд. Как только появляется новое сообщение — сразу возвращает ответ. Если за 30 секунд ничего не пришло — возвращает пустой массив, и скрипт делает новый запрос. Каждое полученное сообщение дописывается в diary.md.
Почему long polling: просто настроить — не нужен webhook с HTTPS и публичным доменом, хотя домен я и использую для связи с ChatGPT. Сообщения приходят мгновенно, а не раз в N секунд. Если сервер перезагрузился — скрипт просто продолжает работать с последнего сообщения.
async function getUpdates(offset) {
// timeout=30 — ждать до 30 секунд, пока не появится сообщение
const url = `https://api.telegram.org/bot${BOT_TOKEN}/getUpdates?offset=${offset}&timeout=30`;
const response = await fetch(url);
const data = await response.json();
return data.result || [];
}Сохранение сообщений в файл
Скрипт ловит каждое новое сообщение и дописывает его в файл diary.md с датой и временем. Если редактирую сообщение в Telegram — скрипт находит запись по ID и обновляет текст.
Пример сохранненого сообщения
#12
дата: 03.01.2026 14:40
Сегодня тренировка. Бег 400м, жим стоя...ID нужен для редактирования. Дата берётся автоматически из времени отправки.
// Telegram возвращает объект message с полями:
// message.message_id — уникальный ID сообщения
// message.date — timestamp в секундах
// message.text — текст сообщения
function appendToDiary(message) {
const msgId = message.message_id;
const date = formatDateTime(message.date);
const text = message.text;
const entry = `#${msgId}\nдата: ${date}\n${text}\n\n`;
const existing = fs.readFileSync('diary.md', 'utf8');
fs.writeFileSync('diary.md', existing + entry);
}
function formatDateTime(timestamp) {
const date = new Date(timestamp * 1000);
const day = String(date.getDate()).padStart(2, '0');
const month = String(date.getMonth() + 1).padStart(2, '0');
const year = date.getFullYear();
const hours = String(date.getHours()).padStart(2, '0');
const minutes = String(date.getMinutes()).padStart(2, '0');
return `${day}.${month}.${year} ${hours}:${minutes}`;
}Настройка сервера
У меня уже есть VPS и собственные домены, ничего покупать дополнительно не пришлось. Дальше я настроил A-запись на поддомене специально для этого проекта. На сервере выпустил SSL-сертификат через certbot:
sudo certbot --apache -d site.comСкрипт запустил как systemd-сервис, чтобы работал постоянно и перезапускался при падении. Создал конфиг /etc/systemd/system/telegram-diary.service и включил его через systemctl enable.
Роутинг для ChatGPT
Настроил два эндпоинта в Apache. /diary отдаёт файл как markdown — удобно открывать в браузере и читать самому. /diary/raw отдаёт тот же файл как plain text — этот формат лучше читает ChatGPT.
# /diary → markdown
RewriteRule ^/diary$ /diary.md [L]
# /diary/raw → plain text
Alias /diary/raw /var/www/diary/diary.md
<Location /diary/raw>
ForceType "text/plain; charset=utf-8"
</Location>Интеграция с ChatGPT
Ссылку на https://site.com/diary/raw добавил в раздел «Персонализация» в настройках ChatGPT. Но есть нюанс: автоматически по ссылке он не переходит. В начале диалога нужно попросить: «Открой ссылку и проанализируй дневник». После этого он читает файл и дальше отвечает с учётом контекста.
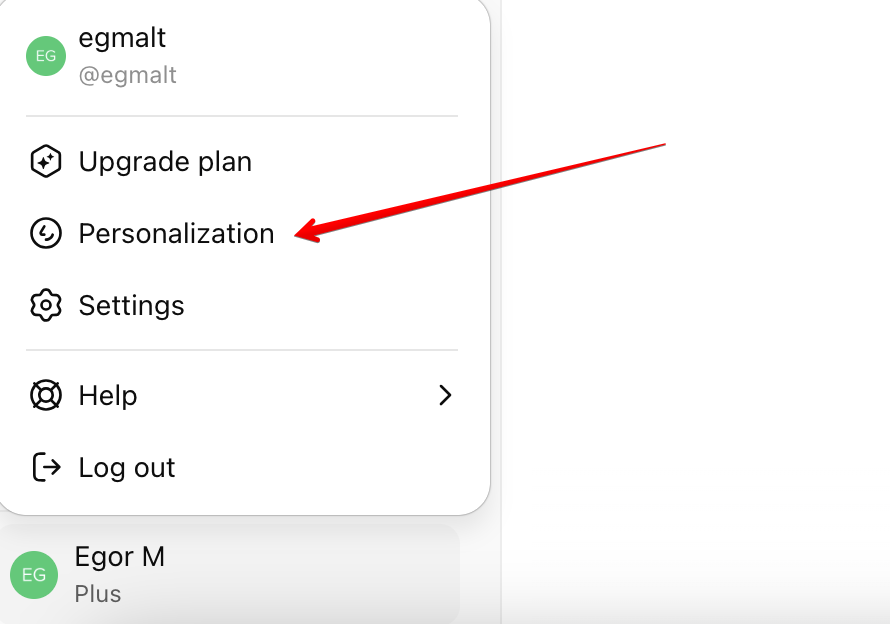
Можно создать Custom GPT и настроить там Action, который автоматически загружает файл при каждом разговоре. Но у Custom GPT нет доступа к Memory аккаунта — он не помнит предыдущие разговоры. Для меня важнее память, поэтому использую обычный ChatGPT с ручным запросом в начале диалога.